7.2 Interpolation using polynomials
#%config InlineBackend.figure_format = 'svg'
from pylab import *
from scipy.interpolate import barycentric_interpolate
Polynomials are easy to evluate since they require only basic arithmetic operations: − , + , ÷ -,+,\div − , + , ÷
7.2.1 Interpolation using monomials ¶ Given N + 1 N+1 N + 1
( x i , y i ) , i = 0 , 1 , … , N with y i = f ( x i ) (x_i, y_i), \quad i=0,1,\ldots,N \qquad \textrm{with} \qquad y_i = f(x_i) ( x i , y i ) , i = 0 , 1 , … , N with y i = f ( x i ) we can try to find a polynomial of degree N N N
p ( x ) = a 0 + a 1 x + … + a N x N p(x) = a_0 + a_1 x + \ldots + a_N x^N p ( x ) = a 0 + a 1 x + … + a N x N that satisfies the interpolation conditions
p ( x i ) = y i , i = 0 , 1 , … , N p(x_i) = y_i, \qquad i=0,1,\ldots, N p ( x i ) = y i , i = 0 , 1 , … , N This is a linear system of N + 1 N+1 N + 1
[ 1 x 0 x 0 2 … x 0 N 1 x 1 x 1 2 … x 1 N ⋮ ⋮ … ⋮ 1 x N x N 2 … x N N ] ⏟ V [ a 0 a 1 ⋮ a N ] = [ y 0 y 1 ⋮ y N ] \underbrace{\begin{bmatrix}
1 & x_0 & x_0^2 & \ldots & x_0^N \\
1 & x_1 & x_1^2 & \ldots & x_1^N \\
\vdots & \vdots & \ldots & \vdots \\
1 & x_N & x_N^2 & \ldots & x_N^N
\end{bmatrix}}_{V}
\begin{bmatrix}
a_0 \\ a_1 \\ \vdots \\ a_N \end{bmatrix} =
\begin{bmatrix}
y_0 \\ y_1 \\ \vdots \\ y_N \end{bmatrix} V ⎣ ⎡ 1 1 ⋮ 1 x 0 x 1 ⋮ x N x 0 2 x 1 2 … x N 2 … … ⋮ … x 0 N x 1 N x N N ⎦ ⎤ ⎣ ⎡ a 0 a 1 ⋮ a N ⎦ ⎤ = ⎣ ⎡ y 0 y 1 ⋮ y N ⎦ ⎤ This has a unique solution if the Vandermonde matrix V V V
det V = ∏ j = 0 N ∏ k = j + 1 N ( x k − x j ) \det V = \prod_{j=0}^N \prod_{k=j+1}^N (x_k - x_j) det V = j = 0 ∏ N k = j + 1 ∏ N ( x k − x j ) we can solve the problem provided the points { x i } \{ x_i \} { x i }
V V V { x i } \{ x_i \} { x i } V a = 0 Va=0 Va = 0 a = 0 a=0 a = 0 N + 1 N+1 N + 1 V a = 0 Va=0 Va = 0
p ( x i ) = 0 , i = 0 , 1 , … , N p(x_i) = 0, \qquad i=0,1,\ldots,N p ( x i ) = 0 , i = 0 , 1 , … , N which implies that p ( x ) p(x) p ( x ) N + 1 N+1 N + 1 p p p N N N p ( x ) ≡ 0 p(x) \equiv 0 p ( x ) ≡ 0 a i = 0 a_i = 0 a i = 0 V V V
7.2.1.1 Condition number of V V V ¶ If we want to solve the interpolation problem by solving the matrix problem, then the condition number of the matrix becomes important. The condition number of a square matrix wrt some matrix norm is defined as
κ ( A ) = ∥ A ∥ ⋅ ∥ A − 1 ∥ \kappa(A) = \norm{A} \cdot \norm{A^{-1}} κ ( A ) = ∥ A ∥ ⋅ ∥ A − 1 ∥ Matrices with large condition numbers cannot be solved accurately on a computer by Gaussian elimination due to possible growth of round-off errors.
Take ( x 0 , x 1 , x 2 ) = ( 100 , 101 , 102 ) (x_0,x_1,x_2) = (100,101,102) ( x 0 , x 1 , x 2 ) = ( 100 , 101 , 102 ) p ( x ) = a 0 + a 1 x + a 2 x 2 p(x) = a_0 + a_1 x + a_2 x^2 p ( x ) = a 0 + a 1 x + a 2 x 2
V = [ 1 100 10000 1 101 10201 1 102 10402 ] , cond ( V ) ≈ 1 0 8 V = \begin{bmatrix}
1 & 100 & 10000 \\
1 & 101 & 10201 \\
1 & 102 & 10402 \end{bmatrix}, \qquad \cond(V) \approx 10^8 V = ⎣ ⎡ 1 1 1 100 101 102 10000 10201 10402 ⎦ ⎤ , cond ( V ) ≈ 1 0 8 If we scale the x x x x → x x 0 x \to \frac{x}{x_0} x → x 0 x p ( x ) = a 0 + a 1 ( x / x 0 ) + a 2 ( x / x 0 ) 2 p(x) = a_0 + a_1 (x/x_0) + a_2 (x/x_0)^2 p ( x ) = a 0 + a 1 ( x / x 0 ) + a 2 ( x / x 0 ) 2
V ~ = [ 1 1.00 1.0000 1 1.01 1.0201 1 1.02 1.0402 ] , cond ( V ~ ) ≈ 1 0 5 \tilde{V} = \begin{bmatrix}
1 & 1.00 & 1.0000 \\
1 & 1.01 & 1.0201 \\
1 & 1.02 & 1.0402 \end{bmatrix}, \qquad \cond(\tilde{V}) \approx 10^5 V ~ = ⎣ ⎡ 1 1 1 1.00 1.01 1.02 1.0000 1.0201 1.0402 ⎦ ⎤ , cond ( V ~ ) ≈ 1 0 5 Or we can shift the origin to x 0 x_0 x 0 p ( x ) = a 0 + a 1 ( x − x 0 ) + a 2 ( x − x 0 ) 2 p(x) = a_0 + a_1 (x-x_0) + a_2 (x-x_0)^2 p ( x ) = a 0 + a 1 ( x − x 0 ) + a 2 ( x − x 0 ) 2
V ^ = [ 1 0 0 1 1 1 1 2 4 ] , cond ( V ^ ) ≈ 14 \hat{V} = \begin{bmatrix}
1 & 0 & 0 \\
1 & 1 & 1 \\
1 & 2 & 4 \end{bmatrix}, \qquad \cond(\hat{V}) \approx 14 V ^ = ⎣ ⎡ 1 1 1 0 1 2 0 1 4 ⎦ ⎤ , cond ( V ^ ) ≈ 14 The condition number can be improved by scaling and/or shifting the variables.
It is usually better to map the data to the interval [ − 1 , + 1 ] [-1,+1] [ − 1 , + 1 ] [ 0 , 1 ] [0,1] [ 0 , 1 ] x 0 < x 1 < … x N x_0 < x_1 < \ldots
x_N x 0 < x 1 < … x N
ξ = x − x 0 x N − x 0 \xi = \frac{x - x_0}{x_N - x_0} ξ = x N − x 0 x − x 0 and find a polynomial of the form
p ( ξ ) = a 0 + a 1 ξ + … + a N ξ N p(\xi) = a_0 + a_1 \xi + \ldots + a_N \xi^N p ( ξ ) = a 0 + a 1 ξ + … + a N ξ N But still the condition number increases rapidly with N N N N = 20 N=20 N = 20 8 × 1 0 8 8 \times 10^8 8 × 1 0 8 [ − 1 , + 1 ] [-1,+1] [ − 1 , + 1 ]
We will use the numpy.linalg.cond
Nvalues, Cvalues = [], []
for N in range(1,30):
x = linspace(-1.0,+1.0,N+1)
V = zeros((N+1,N+1))
for j in range(0,N+1):
V[:,j] = x**j
Nvalues.append(N), Cvalues.append(cond(V))
semilogy(Nvalues, Cvalues, 'o-')
xlabel('N'), ylabel('cond(V)'), grid(True);The condition number is large for even moderate value of N = 30 N=30 N = 30
7.2.2 Interpolating polynomials ¶ 7.2.3 Lagrange interpolation ¶ Lagrange interpolation provides the solution without having to solve a
matrix problem. Define
π i ( x ) = ( x − x 0 ) … ( x − x i − 1 ) ( x − x i + 1 ) … ( x − x N ) \pi_i(x) = (x-x_0) \ldots (x-x_{i-1})(x-x_{i+1})\ldots (x-x_N) π i ( x ) = ( x − x 0 ) … ( x − x i − 1 ) ( x − x i + 1 ) … ( x − x N ) and
ℓ i ( x ) = π i ( x ) π i ( x i ) \ell_i(x) = \frac{\pi_i(x)}{\pi_i(x_i)} ℓ i ( x ) = π i ( x i ) π i ( x ) Note that
each ℓ i \ell_i ℓ i N N N
ℓ i ( x j ) = δ i j \ell_i(x_j) = \delta_{ij} ℓ i ( x j ) = δ ij
ℓ i ( x i ) = 1 and ℓ i ( x j ) = 0 , j ≠ i \ell_i(x_i) = 1 \qquad \textrm{and} \qquad \ell_i(x_j) = 0, \quad j \ne i ℓ i ( x i ) = 1 and ℓ i ( x j ) = 0 , j = i Then consider the polynomial of degree N N N
p N ( x ) = ∑ j = 0 N y j ℓ j ( x ) p_N(x) = \sum_{j=0}^N y_j \ell_j(x) p N ( x ) = j = 0 ∑ N y j ℓ j ( x ) By construction this satisfies
p N ( x i ) = y i , i = 0 , 1 , … , N p_N(x_i) = y_i, \qquad i=0,1,\ldots,N p N ( x i ) = y i , i = 0 , 1 , … , N and hence is the solution to the interpolation problem.
Initially, let us use some python functions to compute the interpolating polynomial. In particular, we use scipy.interpolate.barycentric_interpolate
f ( x ) = cos ( 4 π x ) , x ∈ [ 0 , 1 ] f(x) = \cos(4\pi x), \qquad x \in [0,1] f ( x ) = cos ( 4 π x ) , x ∈ [ 0 , 1 ] Define the function
xmin, xmax = 0.0, 1.0
f = lambda x: cos(4*pi*x)
Make a grid and evaluate function at those points.
N = 8 # is the degree, we need N+1 points
x = linspace(xmin, xmax, N+1)
y = f(x)
Now we evaluate this on larger grid for better visualization
M = 100
xe = linspace(xmin, xmax, M)
ye = f(xe) # exact function
yp = barycentric_interpolate(x, y, xe)
plot(x,y,'o',xe,ye,'--',xe,yp,'-')
legend(('Data points','Exact function','Polynomial'))
grid(True), title('Degree '+str(N)+' interpolation');Interpolate the following functions on uniformly spaced points
f ( x ) = cos ( x ) , x ∈ [ 0 , 2 π ] f(x) = \cos(x), \qquad x \in [0,2\pi] f ( x ) = cos ( x ) , x ∈ [ 0 , 2 π ] for N = 2 , 4 , 6 , … , 12 N=2,4,6,\ldots,12 N = 2 , 4 , 6 , … , 12
xmin, xmax = 0.0, 2.0*pi
fun = lambda x: cos(x)
xx = linspace(xmin,xmax,100);
ye = fun(xx);
figure(figsize=(9,8))
for i in range(1,7):
N = 2*i;
subplot(3,2,i)
x = linspace(xmin,xmax,N+1);
y = fun(x);
yy = barycentric_interpolate(x,y,xx);
plot(x,y,'o',xx,ye,'--',xx,yy);
axis([xmin, xmax, -1.1, +1.1])
text(3.0,0.0,'N='+str(N),ha='center');The interpolating polynomials seem to converge to the true function as N N N
7.2.4 Error estimate ¶ Let p N ( x ) p_N(x) p N ( x ) N N N ( x i , y i ) (x_i,y_i) ( x i , y i ) i = 0 , 1 , … , N i=0,1,\ldots,N i = 0 , 1 , … , N
e N ( x ) = f ( x ) − p N ( x ) e_N(x) = f(x) - p_N(x) e N ( x ) = f ( x ) − p N ( x ) is bounded by
∣ e N ( x ) ∣ ≤ M N + 1 ( N + 1 ) ! ∣ ω N ( x ) ∣ |e_N(x)| \le \frac{M_{N+1}}{(N+1)!} |\omega_N(x)| ∣ e N ( x ) ∣ ≤ ( N + 1 )! M N + 1 ∣ ω N ( x ) ∣ where
ω N ( x ) = ( x − x 0 ) ( x − x 1 ) … ( x − x N ) , M N + 1 = max x ∈ I ( x 0 , … , x N ) ∣ f ( N + 1 ) ( x ) ∣ \omega_N(x) = (x-x_0)(x-x_1)\ldots(x-x_N), \qquad
M_{N+1} = \max_{x \in I(x_0,\ldots,x_N)}|f^{(N+1)}(x)| ω N ( x ) = ( x − x 0 ) ( x − x 1 ) … ( x − x N ) , M N + 1 = x ∈ I ( x 0 , … , x N ) max ∣ f ( N + 1 ) ( x ) ∣ where I ( x 0 , … , x N ) = [ min { x 0 , … , x N } , max { x 0 , … , x N } ] I(x_0,\ldots,x_N) = [\min\{x_0,\ldots,x_N\}, \max\{x_0,\ldots,x_N\}] I ( x 0 , … , x N ) = [ min { x 0 , … , x N } , max { x 0 , … , x N }]
Assume for simplicity that x 0 < x 1 < … < x N x_0 < x_1 < \ldots < x_N x 0 < x 1 < … < x N
e N ( x i ) = 0 , i = 0 , 1 , … , N e_N(x_i) = 0, \qquad i=0,1,\ldots,N e N ( x i ) = 0 , i = 0 , 1 , … , N we can write the error as
e N ( x ) = f ( x ) − p N ( x ) = ω N ( x ) K ( x ) e_N(x) = f(x) - p_N(x) = \omega_N(x) K(x) e N ( x ) = f ( x ) − p N ( x ) = ω N ( x ) K ( x ) for some function K ( x ) K(x) K ( x ) x ∗ ∈ [ x 0 , x N ] x_* \in [x_0,x_N] x ∗ ∈ [ x 0 , x N ] x i x_i x i
Φ ( x ) = f ( x ) − p N ( x ) − ω N ( x ) K ( x ∗ ) \Phi(x) = f(x) - p_N(x) - \omega_N(x) K(x_*) Φ ( x ) = f ( x ) − p N ( x ) − ω N ( x ) K ( x ∗ ) If f ( x ) f(x) f ( x ) ( N + 1 ) (N+1) ( N + 1 ) N + 1 N+1 N + 1 x x x
Φ ( N + 1 ) ( x ) = f ( N + 1 ) ( x ) − ( N + 1 ) ! K ( x ∗ ) \Phi^{(N+1)}(x) = f^{(N+1)}(x) - (N+1)! K(x_*) Φ ( N + 1 ) ( x ) = f ( N + 1 ) ( x ) − ( N + 1 )! K ( x ∗ ) Clearly, Φ ( x ) \Phi(x) Φ ( x ) N + 2 N+2 N + 2 { x 0 , x 1 , … , x N , x ∗ } \{x_0,x_1,\ldots,x_N,x_*\} { x 0 , x 1 , … , x N , x ∗ }
Φ ′ ( x ) \Phi'(x) Φ ′ ( x ) N + 1 N+1 N + 1 [ x 0 , x N ] [x_0,x_N] [ x 0 , x N ]
Φ ′ ′ ( x ) \Phi''(x) Φ ′′ ( x ) N N N [ x 0 , x N ] [x_0,x_N] [ x 0 , x N ]
...
Φ ( N + 1 ) ( x ) \Phi^{(N+1)}(x) Φ ( N + 1 ) ( x ) x ˉ ∈ [ x 0 , x N ] \bar{x} \in [x_0,x_N] x ˉ ∈ [ x 0 , x N ]
Then
f ( N + 1 ) ( x ˉ ) − ( N + 1 ) ! K ( x ∗ ) = 0 ⟹ K ( x ∗ ) = 1 ( N + 1 ) ! f ( N + 1 ) ( x ˉ ) f^{(N+1)}(\bar{x}) - (N+1)! K(x_*) = 0 \quad\Longrightarrow\quad K(x_*) = \frac{1}
{(N+1)!} f^{(N+1)}(\bar{x}) f ( N + 1 ) ( x ˉ ) − ( N + 1 )! K ( x ∗ ) = 0 ⟹ K ( x ∗ ) = ( N + 1 )! 1 f ( N + 1 ) ( x ˉ ) and hence by (26)
f ( x ∗ ) − p N ( x ∗ ) = 1 ( N + 1 ) ! ω N ( x ∗ ) f ( N + 1 ) ( x ˉ ) f(x_*) - p_N(x_*) = \frac{1}{(N+1)!} \omega_N(x_*) f^{(N+1)}
(\bar{x}) f ( x ∗ ) − p N ( x ∗ ) = ( N + 1 )! 1 ω N ( x ∗ ) f ( N + 1 ) ( x ˉ ) Since x ∗ x_* x ∗ x x x
e N ( x ) = f ( x ) − p N ( x ) = 1 ( N + 1 ) ! ω N ( x ) f ( N + 1 ) ( x ˉ ) e_N(x) = f(x) - p_N(x)
= \frac{1}{(N+1)!} \omega_N(x) f^{(N+1)} (\bar{x}) e N ( x ) = f ( x ) − p N ( x ) = ( N + 1 )! 1 ω N ( x ) f ( N + 1 ) ( x ˉ ) which proves the result.
Let us specialize the error estimate to the case of uniformly spaced
points in the interval [ a , b ] [a,b] [ a , b ]
x i = a + i h , 0 ≤ i ≤ N , h = b − a N x_i = a + i h, \qquad 0 \le i \le N, \qquad h = \frac{b-a}{N} x i = a + ih , 0 ≤ i ≤ N , h = N b − a We have x 0 = a x_0 = a x 0 = a x N = b x_N = b x N = b
Fix an x x x j j j x j ≤ x ≤ x j + 1 x_j \le x \le x_{j+1} x j ≤ x ≤ x j + 1
∣ ( x − x j ) ( x − x j + 1 ) ∣ ≤ 1 4 h 2 |(x-x_j)(x-x_{j+1})| \le \frac{1}{4}h^2 ∣ ( x − x j ) ( x − x j + 1 ) ∣ ≤ 4 1 h 2 Hence
∏ i = 0 N ∣ x − x i ∣ ≤ h 2 4 ∏ i = 0 j − 1 ( x − x i ) ∏ i = j + 2 N ( x i − x ) \prod_{i=0}^N |x - x_i| \le \frac{h^2}{4} \prod_{i=0}^{j-1}(x - x_i) \prod_{i=j+2}^N (x_i - x) i = 0 ∏ N ∣ x − x i ∣ ≤ 4 h 2 i = 0 ∏ j − 1 ( x − x i ) i = j + 2 ∏ N ( x i − x ) Now since x ≤ x j + 1 x \le x_{j+1} x ≤ x j + 1 − x ≤ − x j -x \le -x_j − x ≤ − x j
∏ i = 0 N ∣ x − x i ∣ ≤ h 2 4 ∏ i = 0 j − 1 ( x j + 1 − x i ) ∏ i = j + 2 N ( x i − x j ) \prod_{i=0}^N |x - x_i| \le \frac{h^2}{4} \prod_{i=0}^{j-1}(x_{j+1} - x_i)
\prod_{i=j+2}^N (x_i - x_j) i = 0 ∏ N ∣ x − x i ∣ ≤ 4 h 2 i = 0 ∏ j − 1 ( x j + 1 − x i ) i = j + 2 ∏ N ( x i − x j ) Using
x j + 1 − x i = ( j − i + 1 ) h , x i − x j = ( i − j ) h x_{j+1} - x_i = (j-i+1)h, \qquad x_i - x_j = (i-j)h x j + 1 − x i = ( j − i + 1 ) h , x i − x j = ( i − j ) h the inequality becomes
∏ i = 0 N ∣ x − x i ∣ ≤ h N + 1 4 ∏ i = 0 j − 1 ( j − i + 1 ) ∏ i = j + 2 N ( i − j ) = h N + 1 4 ( j + 1 ) ! ( N − j ) ! \prod_{i=0}^N |x - x_i| \le \frac{h^{N+1}}{4} \prod_{i=0}^{j-1}(j-i+1)
\prod_{i=j+2}^N (i - j) = \frac{h^{N+1}}{4} (j+1)! (N-j)! i = 0 ∏ N ∣ x − x i ∣ ≤ 4 h N + 1 i = 0 ∏ j − 1 ( j − i + 1 ) i = j + 2 ∏ N ( i − j ) = 4 h N + 1 ( j + 1 )! ( N − j )! Finally show that (See Assignment, for proof, see problems collection)
( j + 1 ) ! ( N − j ) ! ≤ N ! , 0 ≤ j ≤ N − 1 (j+1)! (N-j)! \le N!, \qquad 0 \le j \le N-1 ( j + 1 )! ( N − j )! ≤ N ! , 0 ≤ j ≤ N − 1 which completes the proof of the theorem.
Assume that ∣ f ( n ) ( x ) ∣ ≤ M |f^{(n)}(x)| \le M ∣ f ( n ) ( x ) ∣ ≤ M x x x n n n
∣ f ( x ) − p ( x ) ∣ ≤ M h N + 1 4 ( N + 1 ) |f(x) - p(x)| \le \frac{M h^{N+1}}{4(N+1)} ∣ f ( x ) − p ( x ) ∣ ≤ 4 ( N + 1 ) M h N + 1 and the error goes to zero as N → ∞ N \to \infty N → ∞
The error bound follows from the two previous theorems. As N N N h h h
Functions like cos x \cos x cos x sin x \sin x sin x exp ( x ) \exp(x) exp ( x ) f ( x ) = sin ( α x ) f(x) = \sin(\alpha x) f ( x ) = sin ( αx ) ∣ f ( n ) ( x ) ∣ ≤ ∣ α ∣ n |f^{(n)}(x)| \le |\alpha|^n ∣ f ( n ) ( x ) ∣ ≤ ∣ α ∣ n ∣ α ∣ > 1 |\alpha| > 1 ∣ α ∣ > 1 n n n
∣ f ( n ) ( x ) ∣ ≤ C α n , α > 0 |f^{(n)}(x)| \le C \alpha^n, \qquad \alpha > 0 ∣ f ( n ) ( x ) ∣ ≤ C α n , α > 0 then the error estimate gives
∣ f ( x ) − p ( x ) ∣ ≤ C ( α h ) N + 1 4 ( N + 1 ) |f(x) - p(x)| \le \frac{C (\alpha h)^{N+1}}{4(N+1)} ∣ f ( x ) − p ( x ) ∣ ≤ 4 ( N + 1 ) C ( α h ) N + 1 As N N N α h < 1 \alpha h < 1 α h < 1
Modify previous code to apply it to f ( x ) = cos ( 4 x ) f(x) = \cos(4x) f ( x ) = cos ( 4 x ) x ∈ [ 0 , 2 π ] x \in [0,2\pi] x ∈ [ 0 , 2 π ] N N N
Consider interpolating the following two functions on [ − 1 , 1 ] [-1,1] [ − 1 , 1 ]
f 1 ( x ) = exp ( − 5 x 2 ) , f 2 ( x ) = 1 1 + 16 x 2 f_1(x) = \exp(-5x^2), \qquad f_2(x) = \frac{1}{1 + 16 x^2} f 1 ( x ) = exp ( − 5 x 2 ) , f 2 ( x ) = 1 + 16 x 2 1 We will try uniformly spaced points and Chebyshev points.
Let us first plot the two functions.
xmin, xmax = -1.0, +1.0
f1 = lambda x: exp(-5.0*x**2)
f2 = lambda x: 1.0/(1.0+16.0*x**2)
xx = linspace(xmin,xmax,100,True)
figure(figsize=(8,4))
plot(xx,f1(xx),xx,f2(xx))
legend(("$1/(1+16x^2)$", "$\\exp(-5x^2)$"));The two functions look visually similar and both are infinitely differentiable.
def interp(f,points):
xx = linspace(xmin,xmax,100,True);
ye = f(xx);
figure(figsize=(9,8))
for i in range(1,7):
N = 2*i
subplot(3,2,i)
if points == 'uniform':
x = linspace(xmin,xmax,N+1,True)
else:
theta = linspace(0,pi,N+1, True)
x = cos(theta)
y = f(x);
yy = barycentric_interpolate(x,y,xx);
plot(x,y,'o',xx,ye,'--',xx,yy)
axis([xmin, xmax, -1.0, +1.1])
text(-0.1,0.0,'N = '+str(N));
Interpolate f 1 ( x ) f_1(x) f 1 ( x )
Interpolate f 2 ( x ) f_2(x) f 2 ( x )
The above results are not good. Let us try f 2 ( x ) f_2(x) f 2 ( x )
What about interpolating f 1 ( x ) f_1(x) f 1 ( x )
This also seems fine. So uniform points works for one function, Chebyshev points work for both.
7.2.6 Difficulty of polynomial interpolation ¶ Do the polynomial approximations p N p_N p N f f f N → ∞ N \to \infty N → ∞ 1 ( N + 1 ) ! \frac{1}{(N+1)!} ( N + 1 )! 1
7.2.6.1 Size of derivatives ¶ On uniformly spaced points, we have seen the interpolants of cos ( x ) \cos(x) cos ( x ) 1 1 + 16 x 2 \frac{1}{1+16x^2} 1 + 16 x 2 1
Consider f ( x ) = ln ( x ) f(x)=\ln(x) f ( x ) = ln ( x )
f ′ = 1 x f ′ ′ = − 1 x 2 f ′ ′ ′ = 2 ! x 3 ⋮ f ( n ) = ( − 1 ) n − 1 ( n − 1 ) ! x n \begin{aligned}
f' &= \frac{1}{x} \\
f'' &= -\frac{1}{x^2} \\
f''' &= \frac{2!}{x^3} \\
&\vdots \\
f^{(n)} &= \frac{(-1)^{n-1} (n-1)!}{x^n}
\end{aligned} f ′ f ′′ f ′′′ f ( n ) = x 1 = − x 2 1 = x 3 2 ! ⋮ = x n ( − 1 ) n − 1 ( n − 1 )! Even though the curve y = ln ( x ) y=\ln(x) y = ln ( x ) x x x n n n n ! n! n !
This is the general situation; for most functions, some higher order
derivatives tend to grow as n ! n! n ! p N ( x ) p_N(x) p N ( x ) N N N a N N ! a_N N! a N N !
7.2.6.2 Polynomial factor in error bound ¶ The error of polynomial interpolation is given by
f ( x ) − p N ( x ) = ω N ( x ) ( N + 1 ) ! f ( N + 1 ) ( ξ ) f(x) - p_N(x) = \frac{\omega_N(x)}{(N+1)!} f^{(N+1)}(\xi) f ( x ) − p N ( x ) = ( N + 1 )! ω N ( x ) f ( N + 1 ) ( ξ ) where ξ ∈ I ( x 0 , x 1 , … , x N , x ) \xi \in I(x_0,x_1,\ldots,x_N,x) ξ ∈ I ( x 0 , x 1 , … , x N , x )
Case N = 1 N=1 N = 1
In case of linear interpolation
ω 1 ( x ) = ( x − x 0 ) ( x − x 1 ) , h = x 1 − x 0 \omega_1(x) = (x-x_0)(x-x_1), \qquad h = x_1 - x_0 ω 1 ( x ) = ( x − x 0 ) ( x − x 1 ) , h = x 1 − x 0 Then
max x 0 ≤ x ≤ x 1 ∣ ω 1 ( x ) ∣ = h 2 4 \max_{x_0 \le x \le x_1} |\omega_1(x)| = \frac{h^2}{4} x 0 ≤ x ≤ x 1 max ∣ ω 1 ( x ) ∣ = 4 h 2 and the interpolation error bound is
max x 0 ≤ x ≤ x 1 ∣ f ( x ) − p 1 ( x ) ∣ ≤ h 2 8 max x 0 ≤ x ≤ x 1 ∣ f ′ ′ ( x ) ∣ \max_{x_0 \le x \le x_1} |f(x) - p_1(x)| \le \frac{h^2}{8} \max_{x_0 \le x \le x_1}|
f''(x)| x 0 ≤ x ≤ x 1 max ∣ f ( x ) − p 1 ( x ) ∣ ≤ 8 h 2 x 0 ≤ x ≤ x 1 max ∣ f ′′ ( x ) ∣ Case N = 2 N=2 N = 2
To bound ω 2 ( x ) \omega_2(x) ω 2 ( x ) [ x 0 , x 2 ] [x_0,x_2] [ x 0 , x 2 ] x 1 x_1 x 1
ω 2 ( x ) = ( x − h ) x ( x + h ) \omega_2(x) = (x-h)x(x+h) ω 2 ( x ) = ( x − h ) x ( x + h ) Near the center of the data
max x 1 − 1 2 h ≤ x ≤ x 1 + 1 2 h ∣ ω 2 ( x ) ∣ = 0.375 h 3 \max_{x_1-\half h \le x \le x_1 + \half h} |\omega_2(x)| = 0.375 h^3 x 1 − 2 1 h ≤ x ≤ x 1 + 2 1 h max ∣ ω 2 ( x ) ∣ = 0.375 h 3 whereas on the whole interval
max x 0 ≤ x ≤ x 2 ∣ ω 2 ( x ) ∣ = 2 3 9 h 3 ≈ 0.385 h 3 \max_{x_0 \le x \le x_2} |\omega_2(x)| = \frac{2\sqrt{3}}{9}h^3 \approx 0.385 h^3 x 0 ≤ x ≤ x 2 max ∣ ω 2 ( x ) ∣ = 9 2 3 h 3 ≈ 0.385 h 3 In this case, the error is of similar magnitude whether x x x
Case N = 3 N=3 N = 3
We can shift the nodes so that they are symmetric about the origin. Then
ω 3 ( x ) = ( x 2 − 9 4 h 2 ) ( x 2 − 1 4 h 2 ) \omega_3(x) = \left( x^2 - \frac{9}{4}h^2 \right) \left( x^2 - \frac{1}{4}h^2 \right) ω 3 ( x ) = ( x 2 − 4 9 h 2 ) ( x 2 − 4 1 h 2 ) and
max x 1 ≤ x ≤ x 2 ∣ ω 3 ( x ) ∣ = 9 16 h 4 ≈ 0.56 h 4 max x 0 ≤ x ≤ x 3 ∣ ω 3 ( x ) ∣ = h 4 \begin{align}
\max_{x_1 \le x \le x_2}|\omega_3(x)| &= \frac{9}{16}h^4 \approx 0.56 h^4 \\
\max_{x_0 \le x \le x_3}|\omega_3(x)| &= h^4
\end{align} x 1 ≤ x ≤ x 2 max ∣ ω 3 ( x ) ∣ x 0 ≤ x ≤ x 3 max ∣ ω 3 ( x ) ∣ = 16 9 h 4 ≈ 0.56 h 4 = h 4 In this case, the error near the endpoints can be twice as large as the error near the middle.
Case N = 6 N = 6 N = 6
The behaviour exhibited for N = 3 N=3 N = 3 N = 6 N=6 N = 6
max x 2 ≤ x ≤ x 4 ∣ ω 6 ( x ) ∣ ≈ 12.36 h 7 , max x 0 ≤ x ≤ x 6 ∣ ω 6 ( x ) ∣ ≈ 95.8 h 7 \max_{x_2 \le x \le x_4}|\omega_6(x)| \approx 12.36 h^7, \qquad
\max_{x_0 \le x \le x_6}|\omega_6(x)| \approx 95.8 h^7 x 2 ≤ x ≤ x 4 max ∣ ω 6 ( x ) ∣ ≈ 12.36 h 7 , x 0 ≤ x ≤ x 6 max ∣ ω 6 ( x ) ∣ ≈ 95.8 h 7 and the error near the ends can be almost 8 times that near the center.
The next functions evaluate ω N ( x ) \omega_N(x) ω N ( x )
# x = (x0,x1,x2,...,xN)
# xp = array of points where to evaluate
def omega(x,xp):
fp = ones_like(xp)
for xi in x:
fp = fp * (xp - xi)
return fp
def plot_omega(x):
M = 1000
xx = linspace(-1.0,1.0,M)
f = omega(x, xx)
plot(xx,f,'b-',x,0*x,'o')
title("N = "+str(N)), grid(True);
For a given set of points x 0 , x 1 , … , x N ∈ [ − 1 , + 1 ] x_0, x_1, \ldots, x_N \in [-1,+1] x 0 , x 1 , … , x N ∈ [ − 1 , + 1 ]
ω N ( x ) = ( x − x 0 ) ( x − x 1 ) … ( x − x N ) , x ∈ [ − 1 , + 1 ] \omega_N(x) = (x-x_0)(x-x_1) \ldots (x-x_N), \qquad x \in [-1,+1] ω N ( x ) = ( x − x 0 ) ( x − x 1 ) … ( x − x N ) , x ∈ [ − 1 , + 1 ] for uniformly spaced points.
N = 8
x = linspace(-1.0,1.0,N+1)
plot_omega(x)N = 20
x = linspace(-1.0,1.0,N+1)
plot_omega(x)Near the end points, the function ω N \omega_N ω N
7.2.7 Distribution of data points ¶ The error in polynomial interpolation is
∣ f ( x ) − p N ( x ) ∣ ≤ ∣ ω N ( x ) ∣ ( N + 1 ) ! max ξ ∈ [ a , b ] ∣ f ( N + 1 ) ( ξ ) ∣ |f(x) - p_N(x)| \le \frac{|\omega_N(x)|}{(N+1)!} \max_{\xi \in [a,b]} |f^{(N+1)}(\xi)| ∣ f ( x ) − p N ( x ) ∣ ≤ ( N + 1 )! ∣ ω N ( x ) ∣ ξ ∈ [ a , b ] max ∣ f ( N + 1 ) ( ξ ) ∣ For a given function f ( x ) f(x) f ( x ) ω N \omega_N ω N ω N ( x ) \omega_N(x) ω N ( x ) x i x_i x i [ − 1 , + 1 ] [-1,+1] [ − 1 , + 1 ]
Given N N N N + 1 N+1 N + 1 { x i } \{x_i\} { x i } [ − 1 , 1 ] [-1,1] [ − 1 , 1 ]
max x ∈ [ − 1 , + 1 ] ∣ ω N ( x ) ∣ \max_{x \in [-1,+1]} |\omega_N(x)| x ∈ [ − 1 , + 1 ] max ∣ ω N ( x ) ∣ is minimized ?
We will show that
min { x i } max x ∈ [ − 1 , + 1 ] ∣ ω N ( x ) ∣ = 2 − N \min_{\{x_i\}} \max_{x \in [-1,+1]} |\omega_N(x)| = 2^{-N} { x i } min x ∈ [ − 1 , + 1 ] max ∣ ω N ( x ) ∣ = 2 − N and the minimum is achieved for following set of nodes
x i = cos ( 2 ( N − i ) + 1 2 N + 2 π ) , i = 0 , 1 , … , N x_i = \cos\left( \frac{2(N-i)+1}{2N+2} \pi \right), \qquad i=0,1,\ldots,N x i = cos ( 2 N + 2 2 ( N − i ) + 1 π ) , i = 0 , 1 , … , N These are called Chebyshev points of first kind .
7.2.8 Chebyshev polynomials ¶ The Chebyshev polynomials are defined on the interval [ − 1 , + 1 ] [-1,+1] [ − 1 , + 1 ]
T 0 ( x ) = 1 T 1 ( x ) = x \begin{aligned}
T_0(x) &= 1 \\
T_1(x) &= x
\end{aligned} T 0 ( x ) T 1 ( x ) = 1 = x The remaining polynomials can be defined by recursion
T n + 1 ( x ) = 2 x T n ( x ) − T n − 1 ( x ) T_{n+1}(x) = 2 x T_n(x) - T_{n-1}(x) T n + 1 ( x ) = 2 x T n ( x ) − T n − 1 ( x ) so that
T 2 ( x ) = 2 x 2 − 1 T 3 ( x ) = 4 x 3 − 3 x T 4 ( x ) = 8 x 4 − 8 x 2 + 1 \begin{aligned}
T_2(x) &= 2x^2 - 1 \\
T_3(x) &= 4x^3 - 3x \\
T_4(x) &= 8x^4 - 8x^2 + 1
\end{aligned} T 2 ( x ) T 3 ( x ) T 4 ( x ) = 2 x 2 − 1 = 4 x 3 − 3 x = 8 x 4 − 8 x 2 + 1 In Python, we can use function recursion to compute the Chebyshev polynomials.
def chebyshev(n, x):
if n == 0:
y = ones_like(x)
elif n == 1:
y = x.copy()
else:
y = 2 * x * chebyshev(n-1,x) - chebyshev(n-2,x)
return y
The first few of these are shown below.
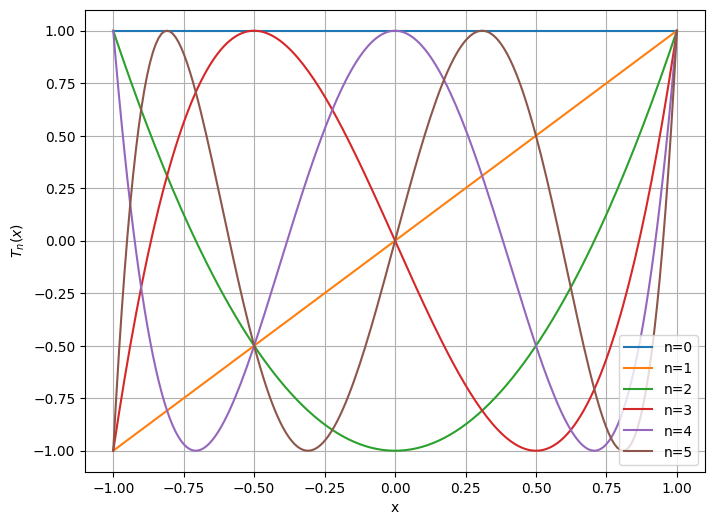
N = 200
x = linspace(-1.0,1.0,N)
figure(figsize=(8,6))
for n in range(0,6):
y = chebyshev(n,x)
plot(x,y,label='n='+str(n))
legend(), grid(True), xlabel('x'), ylabel('$T_n(x)$');We can write x ∈ [ − 1 , + 1 ] x \in [-1,+1] x ∈ [ − 1 , + 1 ] θ ∈ [ 0 , π ] \theta \in [0,\pi] θ ∈ [ 0 , π ]
x = cos θ x=\cos\theta x = cos θ Properties of Chebyshev polynomials
T n ( x ) T_n(x) T n ( x ) n n n
T n ( cos θ ) = cos ( n θ ) T_n(\cos\theta) = \cos(n\theta) T n ( cos θ ) = cos ( n θ )
T n ( x ) = cos ( n cos − 1 ( x ) ) T_n(x) = \cos(n\cos^{-1}(x)) T n ( x ) = cos ( n cos − 1 ( x ))
∣ T n ( x ) ∣ ≤ 1 |T_n(x)| \le 1 ∣ T n ( x ) ∣ ≤ 1
Extrema
T n ( cos ( j π n ) ) = ( − 1 ) j , 0 ≤ j ≤ n T_n\left(\cos\left(\frac{j\pi}{n}\right)\right) = (-1)^j, \qquad 0 \le j \le n T n ( cos ( n jπ ) ) = ( − 1 ) j , 0 ≤ j ≤ n Roots
T n ( cos ( 2 j + 1 2 n π ) ) = 0 , 0 ≤ j ≤ n − 1 T_n\left( \cos \left(\frac{2j+1}{2n}\pi\right) \right) = 0, \qquad 0 \le j \le n-1 T n ( cos ( 2 n 2 j + 1 π ) ) = 0 , 0 ≤ j ≤ n − 1 If p : [ − 1 , 1 ] → R p : [-1,1] \to \re p : [ − 1 , 1 ] → R n n n
∥ p ∥ ∞ = max x ∈ [ − 1 , + 1 ] ∣ p ( x ) ∣ ≥ 2 1 − n \norm{p}_\infty = \max_{x \in[-1,+1]} |p(x)| \ge 2^{1-n} ∥ p ∥ ∞ = x ∈ [ − 1 , + 1 ] max ∣ p ( x ) ∣ ≥ 2 1 − n We prove by contradiction. Suppose that
∣ p ( x ) ∣ < 2 1 − n , ∀ ∣ x ∣ ≤ 1 |p(x)| < 2^{1-n}, \qquad \forall |x| \le 1 ∣ p ( x ) ∣ < 2 1 − n , ∀∣ x ∣ ≤ 1 Define
q ( x ) = 2 1 − n T n ( x ) q(x) = 2^{1-n} T_n(x) q ( x ) = 2 1 − n T n ( x ) The extrema of T n T_n T n
x i = cos ( i π n ) , 0 ≤ i ≤ n x_i = \cos\left( \frac{i\pi}{n} \right), \quad 0 \le i \le n x i = cos ( n iπ ) , 0 ≤ i ≤ n and
T n ( x i ) = ( − 1 ) i so that q ( x i ) = 2 1 − n ( − 1 ) i T_n(x_i) = (-1)^i \qquad \textrm{so that} \qquad q(x_i) = 2^{1-n} (-1)^i T n ( x i ) = ( − 1 ) i so that q ( x i ) = 2 1 − n ( − 1 ) i Now, by assumption
( − 1 ) i p ( x i ) ≤ ∣ p ( x i ) ∣ < 2 1 − n = ( − 1 ) i q ( x i ) (-1)^i p(x_i) \le |p(x_i)| < 2^{1-n} = (-1)^i q(x_i) ( − 1 ) i p ( x i ) ≤ ∣ p ( x i ) ∣ < 2 1 − n = ( − 1 ) i q ( x i ) so that
( − 1 ) i [ q ( x i ) − p ( x i ) ] > 0 , 0 ≤ i ≤ n (-1)^i [q(x_i) - p(x_i)] > 0, \qquad 0 \le i \le n ( − 1 ) i [ q ( x i ) − p ( x i )] > 0 , 0 ≤ i ≤ n q − p q-p q − p n n n n n n q − p q-p q − p n − 1 n-1 n − 1
7.2.9 Optimal nodes ¶ Since ω N ( x ) \omega_N(x) ω N ( x ) N + 1 N+1 N + 1
max − 1 ≤ x ≤ + 1 ∣ ω N ( x ) ∣ ≥ 2 − N \max_{-1 \le x \le +1} |\omega_N(x)| \ge 2^{-N} − 1 ≤ x ≤ + 1 max ∣ ω N ( x ) ∣ ≥ 2 − N Question. Can we choose the x i x_i x i 2 − N 2^{-N} 2 − N
Answer. If { x i } \{x_i\} { x i } N + 1 N+1 N + 1 T N + 1 ( x ) T_{N+1}(x) T N + 1 ( x )
ω N ( x ) = 2 − N T N + 1 ( x ) \omega_N(x) = 2^{-N} T_{N+1}(x) ω N ( x ) = 2 − N T N + 1 ( x ) so that
max − 1 ≤ x ≤ + 1 ∣ ω N ( x ) ∣ = 2 − N max − 1 ≤ x ≤ + 1 ∣ T N + 1 ( x ) ∣ = 2 − N \max_{-1 \le x \le +1} |\omega_N(x)| = 2^{-N} \max_{-1 \le x \le +1} |T_{N+1}(x)| = 2^{-N} − 1 ≤ x ≤ + 1 max ∣ ω N ( x ) ∣ = 2 − N − 1 ≤ x ≤ + 1 max ∣ T N + 1 ( x ) ∣ = 2 − N Thus the optimal nodes are Chebyshev points of first kind
x i = cos ( 2 i + 1 2 N + 2 π ) , 0 ≤ i ≤ N x_i = \cos\left( \frac{2i+1}{2N+2} \pi \right), \qquad 0 \le i \le N x i = cos ( 2 N + 2 2 i + 1 π ) , 0 ≤ i ≤ N In terms of θ \theta θ
θ i + 1 − θ i = π N + 1 \theta_{i+1} - \theta_i = \frac{\pi}{N+1} θ i + 1 − θ i = N + 1 π is constant. With these points, we have
− 1 2 N ≤ ω N ( x ) ≤ 1 2 N , x ∈ [ − 1 , 1 ] -\frac{1}{2^{N}} \le \omega_N(x) \le \frac{1}{2^{N}}, \qquad x \in [-1,1] − 2 N 1 ≤ ω N ( x ) ≤ 2 N 1 , x ∈ [ − 1 , 1 ] The roots of degree n n n T n ( x ) T_n(x) T n ( x )
x i = cos ( 2 i + 1 2 n π ) , i = 0 , 1 , … , n − 1 x_i = \cos\left( \frac{2i+1}{2n} \pi \right), \qquad i=0,1,\ldots,n-1 x i = cos ( 2 n 2 i + 1 π ) , i = 0 , 1 , … , n − 1 The roots are shown below for n = 10 , 11 , … , 19 n=10,11,\ldots,19 n = 10 , 11 , … , 19
c = 1
for n in range(10,20):
j = linspace(0,n-1,n)
theta = (2*j+1)*pi/(2*n)
x = cos(theta)
y = 0*x
subplot(10,1,c)
plot(x,y,'.')
xticks([]); yticks([])
ylabel(str(n))
c += 1Note that the roots are clustered near the end points and are contained in ( − 1 , 1 ) (-1,1) ( − 1 , 1 )
x 0 = cos ( 1 2 N + 2 π ) < 1 , x N = cos ( 2 N + 1 2 N + 2 π ) > − 1 x_0 = \cos\left( \frac{1}{2N+2} \pi \right) < 1, \qquad x_N = \cos\left( \frac{2N+1} {2N+2} \pi \right) > -1 x 0 = cos ( 2 N + 2 1 π ) < 1 , x N = cos ( 2 N + 2 2 N + 1 π ) > − 1 the endpoints of [ − 1 , + 1 ] [-1,+1] [ − 1 , + 1 ] x 0 > x 1 > … > x N x_0 > x_1 > \ldots > x_N x 0 > x 1 > … > x N x i x_i x i (59)
If the nodes { x i } \{x_i\} { x i } N + 1 N+1 N + 1 T N + 1 T_{N+1} T N + 1 [ − 1 , + 1 ] [-1,+1] [ − 1 , + 1 ]
∣ f ( x ) − p N ( x ) ∣ ≤ 1 2 N ( N + 1 ) ! max ∣ t ∣ ≤ 1 ∣ f ( N + 1 ) ( t ) ∣ |f(x) - p_N(x)| \le \frac{1}{2^N (N+1)!} \max_{|t| \le 1}|f^{(N+1)}(t)| ∣ f ( x ) − p N ( x ) ∣ ≤ 2 N ( N + 1 )! 1 ∣ t ∣ ≤ 1 max ∣ f ( N + 1 ) ( t ) ∣ In practice, we dont use the Chebyshev nodes as derived above. The important point is how the points are clustered near the ends of the interval. This type of clustering can be achieved by other node sets. If we want N + 1 N+1 N + 1 [ 0 , π ] [0,\pi] [ 0 , π ] N N N
θ i = ( N − i ) π N , i = 0 , 1 , … , N \theta_i = \frac{(N-i)\pi}{N}, \qquad i=0,1,\ldots,N θ i = N ( N − i ) π , i = 0 , 1 , … , N and then the nodes are given by
x i = cos θ i x_i = \cos\theta_i x i = cos θ i These are called Chebyshev points of second kind . In Python they can be obtained as
theta = linspace(0,pi,N+1)
x = -cos(theta)which returns them in the order
− 1 = x 0 < x 1 < … < x N = + 1 -1 = x_0 < x_1 < \ldots < x_N = +1 − 1 = x 0 < x 1 < … < x N = + 1 They can also be obtained as projections of uniformly spaced points on the unit circle onto the x x x
t = linspace(0,pi,1000)
xx, yy = cos(t), sin(t)
plot(xx,yy)
n = 10
theta = linspace(0,pi,n)
plot(cos(theta),sin(theta),'o')
plot(cos(theta),zeros(n),'sr',label='Chebyshev')
for i in range(n):
x1 = [cos(theta[i]), cos(theta[i])]
y1 = [0.0, sin(theta[i])]
plot(x1,y1,'k--')
plot([-1.1,1.1],[0,0],'-')
legend(), xlabel('x')
axis([-1.1, 1.1, 0.0, 1.1])
axis('equal'), title(str(n)+' Chebyshev points');Below, we compare the polynomial ω N ( x ) \omega_N(x) ω N ( x ) N = 16 N=16 N = 16
M = 1000
xx = linspace(-1.0,1.0,M)
N = 16
xu = linspace(-1.0,1.0,N+1) # uniform points
xc = cos(linspace(0.0,pi,N+1)) # chebyshev points
fu = omega(xu,xx)
fc = omega(xc,xx)
plot(xx,fu,'b-',xx,fc,'r-')
legend(("Uniform","Chebyshev"))
grid(True), title("Degree N = "+str(N));With Chebyshev points, this function is of similar size throughout the interval.