7.9 Piecewise polynomial interpolation
#%config InlineBackend.figure_format = 'svg'
from pylab import *
from matplotlib import animation
from IPython.display import HTML
Consider a partition of [ a , b ] [a,b] [ a , b ]
a = x 0 < x 1 < … < x N = b a = x_0 < x_1 < \ldots < x_N = b a = x 0 < x 1 < … < x N = b The points x j x_j x j p ( x ) p(x) p ( x )
[ x 0 , x 1 ] , [ x 1 , x 2 ] , … , [ x N − 1 , x N ] [x_0,x_1], \quad [x_1,x_2], \quad \ldots, [x_{N-1},x_N] [ x 0 , x 1 ] , [ x 1 , x 2 ] , … , [ x N − 1 , x N ] i.e.,
p ( x ) ∈ P r , x ∈ [ x i , x i + 1 ] p(x) \in \poly_r, \qquad x \in [x_i,x_{i+1}] p ( x ) ∈ P r , x ∈ [ x i , x i + 1 ] Note that p ( x ) p(x) p ( x ) [ a , b ] [a, b] [ a , b ]
We say that p : [ a , b ] → R p: [a,b] \to \re p : [ a , b ] → R r r r p p p r r r
In general, no restrictions on the continuity of p ( x ) p(x) p ( x )
7.9.1 Piecewise linear interpolation ¶ Let us demand the we want a continuous approximation. We are given the function values y i = f ( x i ) y_i = f(x_i) y i = f ( x i )
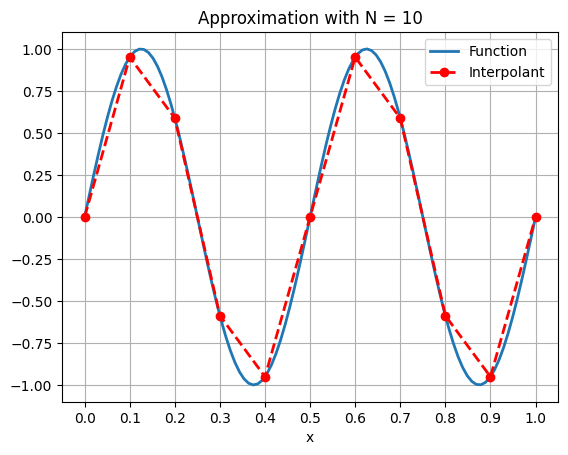
p ( x ) = x − x i + 1 x i − x i + 1 y i + x − x i x i + 1 − x i y i + 1 , x i ≤ x ≤ x i + 1 p(x) = \frac{x - x_{i+1}}{x_i - x_{i+1}} y_i + \frac{x - x_i}{x_{i+1} - x_i} y_{i+1}, \qquad x_i \le x \le x_{i+1} p ( x ) = x i − x i + 1 x − x i + 1 y i + x i + 1 − x i x − x i y i + 1 , x i ≤ x ≤ x i + 1 Clearly, such a function is piecewise linear and continuous in the whole domain. Here is the approximation with N = 10 N=10 N = 10 f ( x ) = sin ( 4 π x ) f(x) = \sin(4 \pi x) f ( x ) = sin ( 4 π x ) x ∈ [ 0 , 1 ] x \in [0,1] x ∈ [ 0 , 1 ]
fun = lambda x: sin(4*pi*x)
xmin, xmax = 0.0, 1.0
N = 10
x = linspace(xmin,xmax,N+1)
f = fun(x)
xe = linspace(xmin,xmax,100) # for plotting only
fe = fun(xe)
fig, ax = subplots()
line1, = ax.plot(xe,fe,'-',linewidth=2,label='Function')
line2, = ax.plot(x,f,'or--',linewidth=2,label='Interpolant')
ax.set_xticks(x), ax.grid()
ax.set_xlabel('x'), ax.legend()
ax.set_title('Approximation with N = ' + str(N));The vertical grid lines show the boundaries of the sub-intervals.
From the error estimate of polynomial interpolation,
f ( x ) − p ( x ) = 1 2 ! ( x − x i ) ( x − x i + 1 ) f ′ ′ ( ξ ) , ξ ∈ [ x i , x i + 1 ] f(x) - p(x) = \frac{1}{2!} (x-x_i)(x - x_{i+1}) f''(\xi), \qquad \xi \in [x_i, x_{i+1}] f ( x ) − p ( x ) = 2 ! 1 ( x − x i ) ( x − x i + 1 ) f ′′ ( ξ ) , ξ ∈ [ x i , x i + 1 ] we get the local interpolation error estimate
max x ∈ [ x i , x i + 1 ] ∣ f ( x ) − p ( x ) ∣ ≤ h i + 1 2 8 max t ∈ [ x i , x i + 1 ] ∣ f ′ ′ ( t ) ∣ , h i + 1 = x i + 1 − x i \max_{x \in [x_i,x_{i+1}]} |f(x) - p(x)| \le \frac{h_{i+1}^2}{8} \max_{t \in
[x_i,x_{i+1}]} |f''(t)|, \qquad h_{i+1} = x_{i+1} - x_i x ∈ [ x i , x i + 1 ] max ∣ f ( x ) − p ( x ) ∣ ≤ 8 h i + 1 2 t ∈ [ x i , x i + 1 ] max ∣ f ′′ ( t ) ∣ , h i + 1 = x i + 1 − x i from which we get the global error
max x ∈ [ a , b ] ∣ f ( x ) − p ( x ) ∣ ≤ h 2 8 max t ∈ [ a , b ] ∣ f ′ ′ ( t ) ∣ , h = max i h i \max_{x \in [a,b]} |f(x) - p(x)| \le \frac{h^2}{8} \max_{t \in [a,b]} |f''(t)|, \qquad h = \max_i h_i x ∈ [ a , b ] max ∣ f ( x ) − p ( x ) ∣ ≤ 8 h 2 t ∈ [ a , b ] max ∣ f ′′ ( t ) ∣ , h = i max h i Clearly, we have convergence as N → ∞ N \to \infty N → ∞ h → 0 h \to 0 h → 0 h h h h / 2 h/2 h /2 1 / 4 1/4 1/4
The polynomial degree is fixed and convergence is achieved because the spacing between the grid points becomes smaller. Note that we only require a condition on the second derivative of the function f f f
The points { x i } \{ x_i \} { x i }
We have written down the polynomial in a piecewise manner but we can also write a global view of the polynomial by defining some basis functions. Since
x ∈ [ x i , x i + 1 ] : p ( x ) = x − x i + 1 x i − x i + 1 y i + x − x i x i + 1 − x i y i + 1 x \in [x_i, x_{i+1}]: \qquad p(x) = \clr{red}{\frac{x - x_{i+1}}{x_i - x_{i+1}}} y_i + \frac{x - x_i}{x_{i+1} - x_i} y_{i+1} x ∈ [ x i , x i + 1 ] : p ( x ) = x i − x i + 1 x − x i + 1 y i + x i + 1 − x i x − x i y i + 1 and similarly
x ∈ [ x i − 1 , x i ] : p ( x ) = x − x i x i − 1 − x i y i − 1 + x − x i − 1 x i − x i − 1 y i x \in [x_{i-1}, x_{i}]: \qquad p(x) = \frac{x - x_{i}}{x_{i-1} - x_{i}} y_{i-1} + \clr{red}{\frac{x - x_{i-1}}{x_{i} - x_{i-1}}} y_{i} x ∈ [ x i − 1 , x i ] : p ( x ) = x i − 1 − x i x − x i y i − 1 + x i − x i − 1 x − x i − 1 y i Let us define
ϕ i ( x ) = { x − x i − 1 x i − x i − 1 , x i − 1 ≤ x ≤ x i x i + 1 − x x i + 1 − x i , x i ≤ x ≤ x i + 1 0 , otherwise \phi_i(x) = \begin{cases}
\frac{x - x_{i-1}}{x_i - x_{i-1}}, & x_{i-1} \le x \le x_i \\
\frac{x_{i+1} - x}{x_{i+1} - x_i}, & x_i \le x \le x_{i+1} \\
0, & \textrm{otherwise}
\end{cases} ϕ i ( x ) = ⎩ ⎨ ⎧ x i − x i − 1 x − x i − 1 , x i + 1 − x i x i + 1 − x , 0 , x i − 1 ≤ x ≤ x i x i ≤ x ≤ x i + 1 otherwise These are triangular hat functions with compact support. Then the piecewise linear approximation is given by
p ( x ) = ∑ i = 0 N y i ϕ i ( x ) , x ∈ [ a , b ] p(x) = \sum_{i=0}^N y_i \phi_i(x), \qquad x \in [a,b] p ( x ) = i = 0 ∑ N y i ϕ i ( x ) , x ∈ [ a , b ] For N = 6 N=6 N = 6
def basis1(x,i,h):
xi = i*h; xl,xr = xi-h,xi+h
y = empty_like(x)
for j in range(len(x)):
if x[j]>xr or x[j] < xl:
y[j] = 0
elif x[j]>xi:
y[j] = (xr - x[j])/h
else:
y[j] = (x[j] - xl)/h
return y
N = 6 # Number of elements
xg = linspace(0.0, 1.0, N+1)
h = 1.0/N
# Finer grid for plotting purpose
x = linspace(0.0,1.0,1000)
fig = figure()
ax = fig.add_subplot(111)
ax.set_xlabel('$x$'); ax.set_ylabel('$\\phi$')
line1, = ax.plot(xg,0*xg,'o-')
line2, = ax.plot(x,0*x,'r-',linewidth=2)
for i in range(N+1):
node = '$x_'+str(i)+'$'
ax.text(xg[i],-0.02,node,ha='center',va='top')
ax.axis([-0.1,1.1,-0.1,1.1])
ax.set_xticks(xg)
grid(True), close()
def fplot(i):
y = basis1(x,i,h)
line2.set_ydata(y)
t = '$\\phi_'+str(i)+'$'
ax.set_title(t)
return line2,
anim = animation.FuncAnimation(fig, fplot, frames=N+1, repeat=False)
HTML(anim.to_jshtml())Note each ϕ i ( x ) \phi_i(x) ϕ i ( x )
ϕ i ( x j ) = { 1 , i = j 0 , i ≠ j \phi_i(x_j) = \begin{cases}
1, & i = j \\
0, & i \ne j
\end{cases} ϕ i ( x j ) = { 1 , 0 , i = j i = j similar to the Lagrange polynomials.
In practice, we should never use the global form (11)
If x ∈ [ x i , x i + 1 ] x \in [x_i, x_{i+1}] x ∈ [ x i , x i + 1 ] ϕ i , ϕ i + 1 \phi_i, \phi_{i+1} ϕ i , ϕ i + 1
p ( x ) = ϕ i ( x ) y i + ϕ i + 1 y i + 1 p(x) = \phi_i(x) y_i + \phi_{i+1} y_{i+1} p ( x ) = ϕ i ( x ) y i + ϕ i + 1 y i + 1 7.9.1.2 An adaptive algorithm ¶ How do we choose the number of elements N N N N N N (6) ∣ f ′ ′ ∣ |f''| ∣ f ′′ ∣
We have to first estimate the error in an interval I i = [ x i − 1 , x i ] I_i = [x_{i-1},x_i] I i = [ x i − 1 , x i ]
h i 2 2 H i , H i ≈ max t ∈ [ x i − 1 , x i ] ∣ f ′ ′ ( t ) ∣ \frac{h_i^2}{2} H_i, \qquad H_i \approx \max_{t \in [x_{i-1},x_i]} |f''(t)| 2 h i 2 H i , H i ≈ t ∈ [ x i − 1 , x i ] max ∣ f ′′ ( t ) ∣ by some finite difference formula H i H_i H i ≤ ϵ \le \epsilon ≤ ϵ h i h_i h i
h i 2 8 H i ≤ ϵ \frac{h_i^2}{8} H_i \le \epsilon 8 h i 2 H i ≤ ϵ If in some interval, it happens that
h i 2 8 H i > ϵ \frac{h_i^2}{8} H_i > \epsilon 8 h i 2 H i > ϵ divide I i I_i I i
[ x i − 1 , 1 2 ( x i − 1 + x i ) ] [ 1 2 ( x i − 1 + x i ) , x i ] \left[ x_{i-1}, \half(x_{i-1}+x_i) \right] \qquad \left[ \half(x_{i-1}+x_i), x_i \right] [ x i − 1 , 2 1 ( x i − 1 + x i ) ] [ 2 1 ( x i − 1 + x i ) , x i ] The derivative in the interval [ x i − 1 , x i ] [x_{i-1},x_i] [ x i − 1 , x i ] { x i − 2 , x i − 1 , x i , x i + 1 } \{x_{i-2},x_{i-1},x_i,x_{i+1}\} { x i − 2 , x i − 1 , x i , x i + 1 } polyfit and finding the maximum value of its second derivative at x i − 1 , x i x_{i-1},x_i x i − 1 , x i H i H_i H i P = polyfit(x,f,3) returns a polynomial in the form
P [ 0 ] ∗ x 3 + P [ 1 ] ∗ x 2 + P [ 2 ] ∗ x + P [ 3 ] P[0]*x^3 + P[1]*x^2 + P[2]*x + P[3] P [ 0 ] ∗ x 3 + P [ 1 ] ∗ x 2 + P [ 2 ] ∗ x + P [ 3 ] whose second derivative is
6 ∗ P [ 0 ] ∗ x + 2 ∗ P [ 1 ] 6*P[0]*x + 2*P[1] 6 ∗ P [ 0 ] ∗ x + 2 ∗ P [ 1 ] We can start with a uniform grid of N N N
Given: f ( x ) , N , ϵ f(x), N, \epsilon f ( x ) , N , ϵ Return: { x i , f i } \{x_i,f_i\} { x i , f i }
Make uniform grid of N N N
In each interval [ x i − 1 , x i ] [x_{i-1},x_i] [ x i − 1 , x i ] e i = 1 2 h i 2 H i e_i = \half h_i^2 H_i e i = 2 1 h i 2 H i
Find interval with maximum error
e k = max i e i e_k = \max_i e_i e k = i max e i If e k > ϵ e_k > \epsilon e k > ϵ [ x k − 1 , x k ] [x_{k-1},x_k] [ x k − 1 , x k ]
Return { x i , f i } \{x_i, f_i\} { x i , f i }
Let us try to approximate
f ( x ) = exp ( − 100 ( x − 1 / 2 ) 2 ) sin ( 4 π x ) , x ∈ [ 0 , 1 ] f(x) = \exp(-100(x-1/2)^2) \sin(4 \pi x), \qquad x \in [0,1] f ( x ) = exp ( − 100 ( x − 1/2 ) 2 ) sin ( 4 π x ) , x ∈ [ 0 , 1 ] with piecewise linear approximation.
xmin, xmax = 0.0, 1.0
fun = lambda x: exp(-100*(x-0.5)**2) * sin(4*pi*x)
Here is the initial approximation.
N = 10 # number of initial intervals
x = linspace(xmin,xmax,N+1)
f = fun(x)
ne = 100
xe = linspace(xmin,xmax,ne)
fe = fun(xe)
fig, ax = subplots()
line1, = ax.plot(xe,fe,'-',linewidth=2)
line2, = ax.plot(x,f,'or--',linewidth=2)
ax.set_title('Initial approximation, N = ' + str(N));The next function performs uniform and adaptive refinement.
def adapt(x,f,nadapt=100,err=1.0e-2,mode=1):
N = len(x) # Number of intervals = N-1
for n in range(nadapt): # Number of adaptive refinement steps
h = x[1:] - x[0:-1]
H = zeros(N-1)
# First element
P = polyfit(x[0:4], f[0:4], 3)
H[0] = max(abs(6*P[0]*x[0:2] + 2*P[1]))
for j in range(1,N-2): # Interior elements
P = polyfit(x[j-1:j+3], f[j-1:j+3], 3)
H[j] = max(abs(6*P[0]*x[j:j+2] + 2*P[1]))
# Last element
P = polyfit(x[N-4:N], f[N-4:N], 3)
H[-1] = max(abs(6*P[0]*x[N-2:N] + 2*P[1]))
elem_err = (1.0/8.0) * h**2 * abs(H)
i = argmax(elem_err); current_err = elem_err[i]
if current_err < err:
print('Satisfied error tolerance, N = ' + str(N))
return x,f
if mode == 0:
# N-1 intervals doubled to 2*(N-1), then there are
# 2*(N-1)+1 = 2*N-1 points
x = linspace(xmin,xmax,2*N-1)
f = fun(x)
else:
x = concatenate([x[0:i+1], [0.5*(x[i]+x[i+1])], x[i+1:]])
f = concatenate([f[0:i+1], [fun(x[i+1])], f[i+1:]])
N = len(x)
return x,f
Let us first try uniform refinement, i.e., we sub-divide every interval.
Satisfied error tolerance, N = 81
and adaptive refinement.
Satisfied error tolerance, N = 33
Here is an animation of adaptive refinement.
def fplot(frame_number,x,f):
x1, f1 = adapt(x,f,nadapt=frame_number,mode=1)
line2.set_data(x1,f1)
ax.set_title('N = '+str(len(x1)))
return line2,
anim = animation.FuncAnimation(fig, fplot, frames=22, fargs=[x,f], repeat=False)
HTML(anim.to_jshtml())The adaptive algorithm puts new points in regions of large gradient, where the resolution is not sufficient, and does not add anything in other regions.
Modify the program by changing the error estimate as follows. Estimate second derivative at x i − 1 x_{i-1} x i − 1 x i − 2 , x i − 1 , x i x_{i-2},x_{i-1},x_i x i − 2 , x i − 1 , x i x i x_i x i x i − 1 , x i , x i + 1 x_{i-1},x_i,x_{i+1} x i − 1 , x i , x i + 1
7.9.2 Piecewise quadratic interpolation ¶ Consider a grid
a = x 0 < x 1 < … < x N = b a = x_0 < x_1 < \ldots < x_N = b a = x 0 < x 1 < … < x N = b and define the mid-points of the intervals
x i − 1 2 = 1 2 ( x i − 1 + x i ) , i = 1 , 2 , … , N x_\imh = \half(x_{i-1} + x_i), \qquad i=1,2,\ldots,N x i − 2 1 = 2 1 ( x i − 1 + x i ) , i = 1 , 2 , … , N We are given the information
y i = f ( x i ) , i = 0 , 1 , … , N y i − 1 2 = f ( x i − 1 2 ) , i = 1 , 2 , … , N \begin{align}
y_i &= f(x_i), \quad & i=0,1,\ldots,N \\
y_\imh &= f(x_\imh), \quad & i=1,2,\ldots,N
\end{align} y i y i − 2 1 = f ( x i ) , = f ( x i − 2 1 ) , i = 0 , 1 , … , N i = 1 , 2 , … , N In the interval I i = [ x i − 1 , x i ] I_i = [x_{i-1},x_i] I i = [ x i − 1 , x i ]
y i − 1 , y i − 1 2 , y i y_{i-1}, y_\imh, y_i y i − 1 , y i − 2 1 , y i and we can determine a quadratic polynomial that interpolates these values
p ( x ) = y i − 1 ϕ 0 ( x − x i − 1 h i ) + y i − 1 2 ϕ 1 ( x − x i − 1 h i ) + y i ϕ 2 ( x − x i − 1 h i ) p(x) = y_{i-1} \phi_0\left(\frac{x-x_{i-1}}{h_i}\right)
+ y_\imh \phi_1\left(\frac{x- x_{i-1}}{h_i}\right)
+ y_i \phi_2\left(\frac{x-x_{i-1}}{h_i}\right) p ( x ) = y i − 1 ϕ 0 ( h i x − x i − 1 ) + y i − 2 1 ϕ 1 ( h i x − x i − 1 ) + y i ϕ 2 ( h i x − x i − 1 ) where ϕ 0 , ϕ 1 , ϕ 2 \phi_0,\phi_1,\phi_2 ϕ 0 , ϕ 1 , ϕ 2
ϕ 0 ( ξ ) = 2 ( ξ − 1 2 ) ( ξ − 1 ) , ϕ 1 ( ξ ) = 4 ξ ( 1 − ξ ) , ϕ 2 ( ξ ) = 2 ξ ( ξ − 1 2 ) \phi_0(\xi) = 2(\xi - \shalf)(\xi - 1), \qquad
\phi_1(\xi) = 4\xi(1 - \xi), \qquad
\phi_2(\xi) = 2\xi(\xi-\shalf) ϕ 0 ( ξ ) = 2 ( ξ − 2 1 ) ( ξ − 1 ) , ϕ 1 ( ξ ) = 4 ξ ( 1 − ξ ) , ϕ 2 ( ξ ) = 2 ξ ( ξ − 2 1 ) Note that the quadratic interpolation is continuous but may not be differentiable.
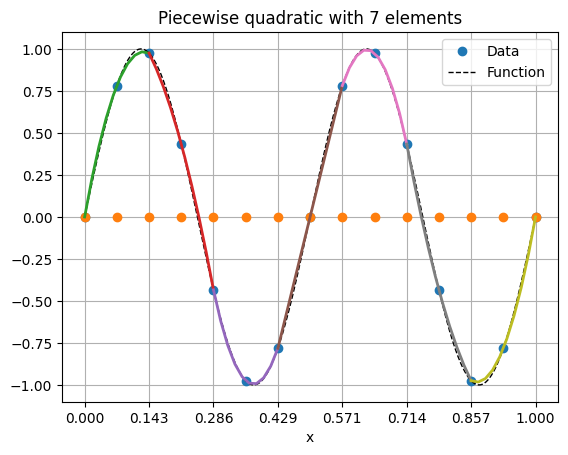
Here is the piecewise quadratic approximation of f ( x ) = sin ( 4 π x ) f(x) = \sin(4 \pi x) f ( x ) = sin ( 4 π x )
fun = lambda x: sin(4*pi*x)
xmin, xmax = 0.0, 1.0
N = 7 # no of elements
m = 2*N + 1 # no of data
x = linspace(xmin,xmax,m)
f = fun(x)
xe = linspace(xmin,xmax,500)
fe = fun(xe)
plot(x,f,'o',label='Data')
plot(x,0*f,'o')
plot(xe,fe,'k--',lw=1,label='Function')
# Local coordinates
xi = linspace(0,1,10)
phi0 = lambda x: 2*(x - 0.5)*(x - 1.0)
phi1 = lambda x: 4*x*(1.0 - x)
phi2 = lambda x: 2*x*(x - 0.5)
j = 0
for i in range(N):
z = x[j:j+3]
h = z[-1] - z[0]
y = f[j:j+3]
fu = y[0]*phi0(xi) + y[1]*phi1(xi) + y[2]*phi2(xi)
plot(xi*h + z[0], fu, lw=2)
j += 2
title('Piecewise quadratic with '+str(N)+' elements')
legend(), xticks(x[::2]), grid(True), xlabel('x');The vertical grid lines show the elements. The quadratic interpolant is shown in different color inside each element.
We can write the approximation in the form
p ( x ) = ∑ k = 0 2 N z k Φ k ( x ) , x ∈ [ a , b ] p(x) = \sum_{k=0}^{2N} z_k \Phi_k(x), \qquad x \in [a,b] p ( x ) = k = 0 ∑ 2 N z k Φ k ( x ) , x ∈ [ a , b ] where
z = ( y 0 , y 1 2 , y 1 , … , y N − 1 , y N − 1 / 2 , y N ) ∈ R 2 N + 1 z = (y_0, y_\half, y_1, \ldots, y_{N-1}, y_{N-1/2}, y_N) \in \re^{2N+1} z = ( y 0 , y 2 1 , y 1 , … , y N − 1 , y N − 1/2 , y N ) ∈ R 2 N + 1 but this form should not be used in computations. For any x ∈ [ x i − 1 , x i ] x \in [x_{i-1},x_i] x ∈ [ x i − 1 , x i ] (26)
7.9.3 Piecewise degree k k k ¶ Consider a grid
a = x 0 < x 1 < … < x N = b a = x_0 < x_1 < \ldots < x_N = b a = x 0 < x 1 < … < x N = b In each interval [ x i − 1 , x i ] [x_{i-1},x_i] [ x i − 1 , x i ] k k k k + 1 k+1 k + 1 k + 1 k+1 k + 1
x i − 1 = x i , 0 < x i , 1 < … < x i , k = x i x_{i-1} = x_{i,0} < x_{i,1} < \ldots < x_{i,k} = x_i x i − 1 = x i , 0 < x i , 1 < … < x i , k = x i Then the degree k k k
p ( x ) = ∑ j = 0 k f ( x i , j ) ϕ j ( x − x i − 1 h i ) p(x) = \sum_{j=0}^k f(x_{i,j}) \phi_j\left( \frac{x-x_{i-1}}{h_i} \right) p ( x ) = j = 0 ∑ k f ( x i , j ) ϕ j ( h i x − x i − 1 ) where ϕ j : [ 0 , 1 ] → R \phi_j : [0,1] \to \re ϕ j : [ 0 , 1 ] → R
ϕ j ( ξ ) = ∏ l = 0 , l ≠ j k ξ − ξ l ξ j − ξ l , ξ l = x i , l − x i − 1 h i \phi_j(\xi) = \prod_{l=0, l \ne j}^k \frac{\xi - \xi_l}{\xi_j - \xi_l}, \qquad
\xi_l = \frac{x_{i,l} - x_{i-1}}{h_i} ϕ j ( ξ ) = l = 0 , l = j ∏ k ξ j − ξ l ξ − ξ l , ξ l = h i x i , l − x i − 1 with the property
ϕ j ( ξ l ) = δ j l , 0 ≤ j , l ≤ k \phi_j(\xi_l) = \delta_{jl}, \quad 0 \le j,l \le k ϕ j ( ξ l ) = δ j l , 0 ≤ j , l ≤ k Since we choose the nodes in each interval such that x i , 0 = x i − 1 x_{i,0} = x_{i-1} x i , 0 = x i − 1 x i , k = x i x_{i,k} = x_i x i , k = x i
Note that we have mapped the interval [ x i − 1 , x i ] [x_{i-1},x_i] [ x i − 1 , x i ] [ 0 , 1 ] [0,1] [ 0 , 1 ]
The points ξ l \xi_l ξ l [ 0 , 1 ] [0,1] [ 0 , 1 ]
In each element, the approximation can be constructed using the data located inside that element only. This lends a local character to the approximation which is useful in Finite Element Methods.
If the function is not smooth in some region, the approximations will be good away from these non-smooth regions. And as we have seen, we can improve the approximation by local grid adaptation.
7.9.4 Error estimate in Sobolev spaces∗ ^* ∗ ¶ The estimate we have derived required functions to be differentiable. Here we use weaker smoothness properties.
Let f ∈ H 2 ( 0 , 1 ) f \in H^2(0,1) f ∈ H 2 ( 0 , 1 ) p ( x ) p(x) p ( x ) f f f
∥ f − p ∥ L 2 ( 0 , 1 ) ≤ C h 2 ∥ f ′ ′ ∥ L 2 ( 0 , 1 ) \norm{f - p}_{L^2(0,1)} \le C h^2 \norm{f''}_{L^2(0,1)} ∥ f − p ∥ L 2 ( 0 , 1 ) ≤ C h 2 ∥ f ′′ ∥ L 2 ( 0 , 1 ) ∥ f ′ − p ′ ∥ L 2 ( 0 , 1 ) ≤ C h ∥ f ′ ′ ∥ L 2 ( 0 , 1 ) \norm{f' - p'}_{L^2(0,1)} \le C h \norm{f''}_{L^2(0,1)} ∥ f ′ − p ′ ∥ L 2 ( 0 , 1 ) ≤ C h ∥ f ′′ ∥ L 2 ( 0 , 1 ) Since C ∞ ( 0 , 1 ) \cts^\infty(0,1) C ∞ ( 0 , 1 ) H 2 ( 0 , 1 ) H^2(0,1) H 2 ( 0 , 1 ) f ∈ C ∞ ( 0 , 1 ) f \in \cts^\infty(0,1) f ∈ C ∞ ( 0 , 1 )
(1) If x ∈ [ x j , x j + 1 ] x \in [x_j, x_{j+1}] x ∈ [ x j , x j + 1 ]
f ( x ) − p ( x ) = f ( x ) − [ f ( x j ) + f ( x j + 1 ) − f ( x j ) x j + 1 − x j ( x − x j ) ] = ∫ x j x f ′ ( t ) d t − x − x j x j + 1 − x j ∫ x j x j + 1 f ′ ( t ) d t = ( x − x j ) f ′ ( x j + θ x ) − ( x − x j ) f ′ ( x j + θ j ) , 0 ≤ θ x ≤ x − x j 0 ≤ θ j ≤ h j = ( x − x j ) ∫ x j + θ j x j + θ x f ′ ′ ( t ) d t \begin{aligned}
f(x) - p(x)
&= f(x) - \left[ f(x_j) + \frac{f(x_{j+1}) - f(x_j)}{x_{j+1} - x_j} (x - x_j)
\right] \\
&= \int_{x_j}^x f'(t) \ud t - \frac{x - x_j}{x_{j+1} - x_j} \int_{x_j}^{x_{j+1}} f'(t)
\ud t \\
&= (x-x_j) f'(x_j + \theta_x) - (x-x_j) f'(x_j + \theta_j), \quad {0 \le \theta_x \le x - x_j
\atop 0 \le \theta_j \le h_j} \\
&= (x-x_j) \int_{x_j + \theta_j}^{x_j + \theta_x} f''(t) \ud t
\end{aligned} f ( x ) − p ( x ) = f ( x ) − [ f ( x j ) + x j + 1 − x j f ( x j + 1 ) − f ( x j ) ( x − x j ) ] = ∫ x j x f ′ ( t ) d t − x j + 1 − x j x − x j ∫ x j x j + 1 f ′ ( t ) d t = ( x − x j ) f ′ ( x j + θ x ) − ( x − x j ) f ′ ( x j + θ j ) , 0 ≤ θ j ≤ h j 0 ≤ θ x ≤ x − x j = ( x − x j ) ∫ x j + θ j x j + θ x f ′′ ( t ) d t Squaring both sides and using ∣ x − x j ∣ ≤ h j |x-x_j| \le h_j ∣ x − x j ∣ ≤ h j
∣ f ( x ) − p ( x ) ∣ 2 ≤ h j 2 [ ∫ x j + θ j x j + θ x f ′ ′ ( t ) d t ] 2 ≤ h j 2 [ ∫ x j x j + 1 ∣ f ′ ′ ( t ) ∣ d t ] 2 ≤ h j 3 ∫ x j x j + 1 ∣ f ′ ′ ( t ) ∣ 2 d t by Cauchy-Schwarz inequality \begin{aligned}
|f(x) - p(x)|^2
&\le h_j^2 \left[ \int_{x_j + \theta_j}^{x_j + \theta_x} f''(t) \ud t
\right]^2 \\
&\le h_j^2 \left[ \int_{x_j}^{x_{j+1}} |f''(t)| \ud t \right]^2 \\
&\le h_j^3 \int_{x_j}^{x_{j+1}} |f''(t)|^2 \ud t \quad \textrm{by Cauchy-Schwarz
inequality}
\end{aligned} ∣ f ( x ) − p ( x ) ∣ 2 ≤ h j 2 [ ∫ x j + θ j x j + θ x f ′′ ( t ) d t ] 2 ≤ h j 2 [ ∫ x j x j + 1 ∣ f ′′ ( t ) ∣ d t ] 2 ≤ h j 3 ∫ x j x j + 1 ∣ f ′′ ( t ) ∣ 2 d t by Cauchy-Schwarz inequality Integrating on [ x j , x j + 1 ] [x_j,x_{j+1}] [ x j , x j + 1 ]
∫ x j x j + 1 ∣ f ( x ) − p ( x ) ∣ 2 d x ≤ h j 4 ∫ x j x j + 1 ∣ f ′ ′ ( t ) ∣ 2 d t \int_{x_j}^{x_{j+1}} |f(x) - p(x)|^2 \ud x \le h_j^4 \int_{x_j}^{x_{j+1}} |f''(t)|^2
\ud t ∫ x j x j + 1 ∣ f ( x ) − p ( x ) ∣ 2 d x ≤ h j 4 ∫ x j x j + 1 ∣ f ′′ ( t ) ∣ 2 d t Adding such an inequality from all the intervals
∥ f − p ∥ L 2 ( 0 , 1 ) 2 ≤ ∑ j h j 4 ∫ x j x j + 1 ∣ f ′ ′ ( t ) ∣ 2 d t ≤ h 4 ∑ j ∫ x j x j + 1 ∣ f ′ ′ ( t ) ∣ 2 d t = h 4 ∥ f ′ ′ ∥ L 2 ( 0 , 1 ) 2 \begin{aligned}
\norm{f-p}_{L^2(0,1)}^2
&\le \sum_j h_j^4 \int_{x_j}^{x_{j+1}} |f''(t)|^2 \ud t \\
&\le h^4 \sum_j \int_{x_j}^{x_{j+1}} |f''(t)|^2 \ud t \\
&= h^4 \norm{f''}_{L^2(0,1)}^2
\end{aligned} ∥ f − p ∥ L 2 ( 0 , 1 ) 2 ≤ j ∑ h j 4 ∫ x j x j + 1 ∣ f ′′ ( t ) ∣ 2 d t ≤ h 4 j ∑ ∫ x j x j + 1 ∣ f ′′ ( t ) ∣ 2 d t = h 4 ∥ f ′′ ∥ L 2 ( 0 , 1 ) 2 we get the first error estimate.
(2) The error in derivative is
f ′ ( x ) − p ′ ( x ) = f ′ ( x ) − f ( x j + 1 ) − f ( x j ) h j = 1 h j ∫ x j x j + 1 [ f ′ ( x ) − f ′ ( t ) ] d t = 1 h j ∫ x j x j + 1 ∫ t x f ′ ′ ( y ) d y d t \begin{aligned}
f'(x) - p'(x)
&= f'(x) - \frac{f(x_{j+1}) - f(x_j)}{h_j} \\
&= \frac{1}{h_j} \int_{x_j}^{x_{j+1}}[f'(x) - f'(t)]\ud t \\
&= \frac{1}{h_j} \int_{x_j}^{x_{j+1}} \int_t^x f''(y) \ud y \ud t
\end{aligned} f ′ ( x ) − p ′ ( x ) = f ′ ( x ) − h j f ( x j + 1 ) − f ( x j ) = h j 1 ∫ x j x j + 1 [ f ′ ( x ) − f ′ ( t )] d t = h j 1 ∫ x j x j + 1 ∫ t x f ′′ ( y ) d y d t Squaring both sides
∣ f ′ ( x ) − p ′ ( x ) ∣ 2 = 1 h j 2 ( ∫ x j x j + 1 ∫ t x f ′ ′ ( y ) d y d t ) 2 ≤ 1 h j 2 ( ∫ x j x j + 1 ∫ t x ∣ f ′ ′ ( y ) ∣ d y d t ) 2 ≤ 1 h j 2 ( ∫ x j x j + 1 ∫ x j x j + 1 ∣ f ′ ′ ( y ) ∣ d y d t ) 2 = ( ∫ x j x j + 1 ∣ f ′ ′ ( y ) ∣ d y ) 2 ≤ h j ∫ x j x j + 1 ∣ f ′ ′ ( y ) ∣ 2 d y by Cauchy-Schwarz inequality \begin{aligned}
|f'(x) - p'(x)|^2
&= \frac{1}{h_j^2} \left( \int_{x_j}^{x_{j+1}} \int_t^x f''(y) \ud y
\ud t \right)^2 \\
&\le \frac{1}{h_j^2} \left( \int_{x_j}^{x_{j+1}} \int_t^x |f''(y)| \ud y \ud t \right)^2
\\
&\le \frac{1}{h_j^2} \left( \int_{x_j}^{x_{j+1}} \int_{x_j}^{x_{j+1}} |f''(y)| \ud y
\ud t \right)^2 \\
&= \left( \int_{x_j}^{x_{j+1}} |f''(y)| \ud y \right)^2 \\
&\le h_j \int_{x_j}^{x_{j+1}} |f''(y)|^2 \ud y \quad \textrm{by Cauchy-Schwarz
inequality}
\end{aligned} ∣ f ′ ( x ) − p ′ ( x ) ∣ 2 = h j 2 1 ( ∫ x j x j + 1 ∫ t x f ′′ ( y ) d y d t ) 2 ≤ h j 2 1 ( ∫ x j x j + 1 ∫ t x ∣ f ′′ ( y ) ∣ d y d t ) 2 ≤ h j 2 1 ( ∫ x j x j + 1 ∫ x j x j + 1 ∣ f ′′ ( y ) ∣ d y d t ) 2 = ( ∫ x j x j + 1 ∣ f ′′ ( y ) ∣ d y ) 2 ≤ h j ∫ x j x j + 1 ∣ f ′′ ( y ) ∣ 2 d y by Cauchy-Schwarz inequality Integrating with respect to x x x
∫ x j x j + 1 ∣ f ′ ( x ) − p ′ ( x ) ∣ 2 d x ≤ h j 2 ∫ x j x j + 1 ∣ f ′ ′ ( y ) ∣ 2 d y \int_{x_j}^{x_{j+1}} |f'(x) - p'(x)|^2 \ud x \le h_j^2 \int_{x_j}^{x_{j+1}} |f''(y)|^2
\ud y ∫ x j x j + 1 ∣ f ′ ( x ) − p ′ ( x ) ∣ 2 d x ≤ h j 2 ∫ x j x j + 1 ∣ f ′′ ( y ) ∣ 2 d y Adding such inequalities from each interval, we obtain the second error estimate.